Welcome to Wang's blog!
-
Software Optimization - Memory Basics
Memory Basics
Modern computer store 64 bits (8 bytes) in its every memory location. Ideally, We can read/write each of byte in each memory location by specifying the address.
The following structure is very basic and is only fit to the single task system.
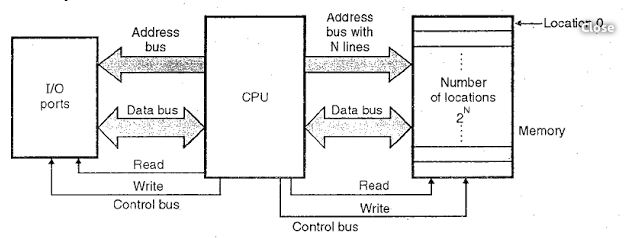
When we start to use multi-tasking system, we need to make sure that each of its program/process cannot access to the memory of other program’s. Memory abstraction(Virtual Memory) is a way to solve this problem. It can also make each process start from same location when they startup, predict and allocate memory space for that process.
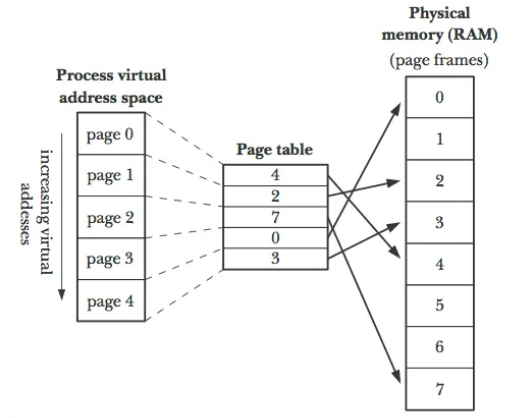
The virtual memory is a logical memory (software based, not physical) and comprises a virtual address space that exists the address space of the RAM. The virtual address space is divided into pages. Pages are consequtive of regions of memory with the same size.
Translation table is used to control the mapping of virtual and actual addresses in physical memory. When a software is trying to access a page, and the page table will show the program where the page is directing to in the RAM. Then, then software can access the data in the corresponding address in RAM.
Advantages of Modern Memory Scheme:
-
Paging/Swapping
- If the user program need more memory that exceeds page1 and need to access page2, but the translation table has no entry for page2. In this case, CPU will throw an exception, transform the control from the user program to kernel. The kernel will search in the physical memory, figure that page2 is not in use right now, then assign it to the translation table and hook it to the user program.
- An interesting point is that we don’t need to assign actual physical pages to all virtual pages we are going to use. We can assign it when we really need to use it. And if a page is not in use for a while, we can move it data to disk drives and reallocate it to another program. It is so called paging or swapping (exchage between RAM and disk).
-
Memory Protection:
- each process has their own memory table/swap
- they cannot see the data stored in the physical memory that is not on their table.
- there are two ways to approach it. one is using only one page table, but each program is allocated into different portition. Another way is each program their own page table.
-
Demand Loading
- Load couple pages for large program, but only for required features, not need for loading whole software.
- e.g. if we only need to use a printf function in this program, we just need to call the page that contains printf and ignore the others
-
Per-Process Data
- Same program call by multiple users, share one executble in memory, but each process gets its own data area.
-
Shared Memory
- Set up a region of memory, and map it to both of addresses
- multiple process can access same block of memory. Very common on multi-threading programs.
-
Shared Text Segments
- Fork()
- -> how we create new process in UNIX system
- -> initially they will have same data
-
Copy-Out-Write(COW)
- When either of two process try to access to a specific page, we need to make a copy of that point.
Physical Memory
I found I very simple explaination about the relationship between CPU, cache and memory
Different cache can talk with each other, to update which is the latest.
Synchronization & Memory Barriers
- make sure changes orders are detected
- special instructions: every write/store before this point of time, has to be visiable to every observer, before any writes/store performed after this point of time. It will make sure the lastest value will be propagated accross the entire system before other values get propagated accross the system. It also guarantee the compiler and cpu not to swap these instructions accoss this barrier.
- x86 force memory ordering (synchronization) accorss the whole system no matter how costs that is all the time.
To Be Continue …
-
-
Software Optimization - SIMD Practice (C Intrinsics)
SIMD C Intrinstics
C Intrinsics are function-like extensions to the C language. Although they look like functions, they are compiled inline. Because C Intrinstics are not provided by C language itself, its function is not portable. We need to be very careful if we want to use it.
-
Software Optimization - SIMD Practice (C Inline)
SIMD C Inline
First of all, let’s look at how C Inline assembler works.
The syntax of C Inline is
__asm__ ("assembley code template" : outputs : inputs : clobbers);It has 4 parameters:
- The assembler template (mandatory)
- Output operands (optional)
- Input operands (optional)
- Clobbers(overwrite) (optional)
Example:
int main() { int a = 3; int b = 19; int c; // __asm__ ("assembley code template" : outputs : outputs : clobbers) __asm__ ("add %0, %1, %2" //%0 = %1 + %2 : "=r"(c) //temp output register %0 value is move to c : "r"(a),"r"(b) ); //input value of a, b is placed into temp input register %1, %2 printf("%d\n", c); }For calculating
c=b%ain AArch64 C Inline assemly We can use:__asm__("udiv %0, %1, %2" : "=r"(c) : "r"(b), "r"(a) ); //c = b/a = 6 __asm__("msub %0, %1, %2, %3" : "=r"(c) : "r"(c), "r"(a), "r"(b) ); //c = 19-(6*3) = 1
-
Software Optimization - SIMD Practice (gcc compiler option)
As we discussed in previous blog Software-Optimization-With-SIMD. We are going to use three methods to see the performance of SIMD vectorization.
- gcc compiler option:
- C Inline
- C Intrinstics
-
Software Optimization - SIMD
SIMD is an acronym for “Single Instruction, Multiple Data”.
When we need to execute a long loop, under certain conditions, we are able to use the SIMD to vectorize the loop into lanes. Then execute the lanes with same instruction in parallel, to make the execution more efficient.
-
UE4 - Map, Mode, Controller
Map, Mode and Controller concept of UE4
- SPO600 Overview
- Program Performence
- OpenCV Optimization Practice - Stage III
- OpenCV Optimization Practice - Stage II Update
- OpenCV Optimization Practice - Stage I Update
- Software Portability and Atomics
- Important Issues for Benchmarking
- ifunc - GNU Indirect Function
- OpenCV Optimization Practice - Stage II
- Software Optimization - Building Software